









一、简介
- 一键递归爬取整个网站并将其保存为一个Markdown格式文本文件
- 支持路径匹配、内容筛选,并且默认支持多线程并发抓取内容
- 开源地址参考:https://github.com/egoist/sitefetch
- 以下是大致的系统结构与工作原理图:
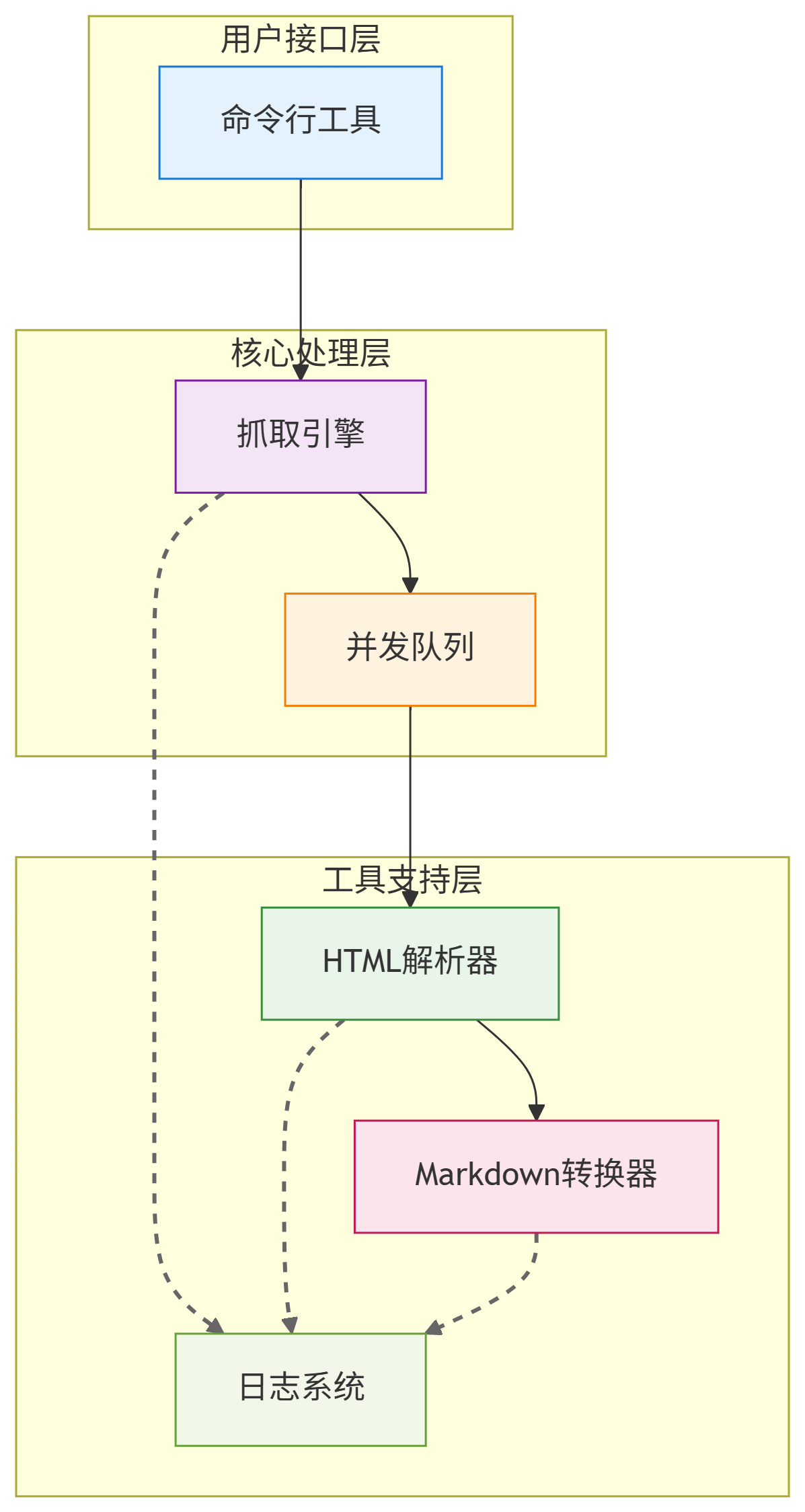
二、安装
- 提前安装好node 18+、npm、npx等软件环境(这里不做赘述)
- 使用npm全局安装
npm i -g sitefetch - 使用npx直接运行
npx sitefetch - 其他不常用方式,类似上面,这里不做介绍,有需要自行参考开源代码页面说明
三、使用示例
-
命令使用范例参考
//抓取face-recognition的使用文档,并把内容保存到face-recognition.txt文件,默认开启3个并发处理 sitefetch https://face-recognition.readthedocs.io/en/latest -o face-recognition.txt //指定并发数量为10 sitefetch https://face-recognition.readthedocs.io/en/latest -o face-recognition.txt --concurrency 10 //指定获取那些页面的路径,如下 sitefetch https://face-recognition.readthedocs.io/en/latest -m "/en/**" -o face-recognition.txt //指定获取页面中CSS选择器中的内容(页面中有些内容是框架固定内容,不是我们想要的,我们只需要页面中某个区域的内容,这个时候有必要指定) sitefetch https://face-recognition.readthedocs.io/en/latest --content-selector ".document" -
命令执行截图
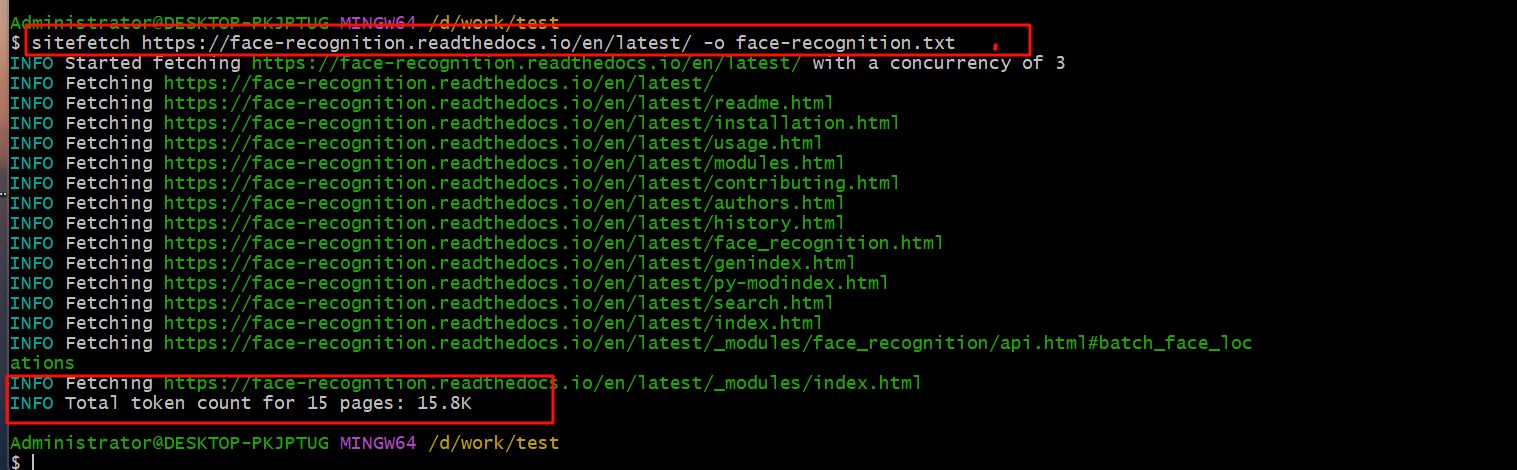
-
抓取到的内容,参考下面截图(该内容特别适合投喂给AI,建立RAG知识库等)
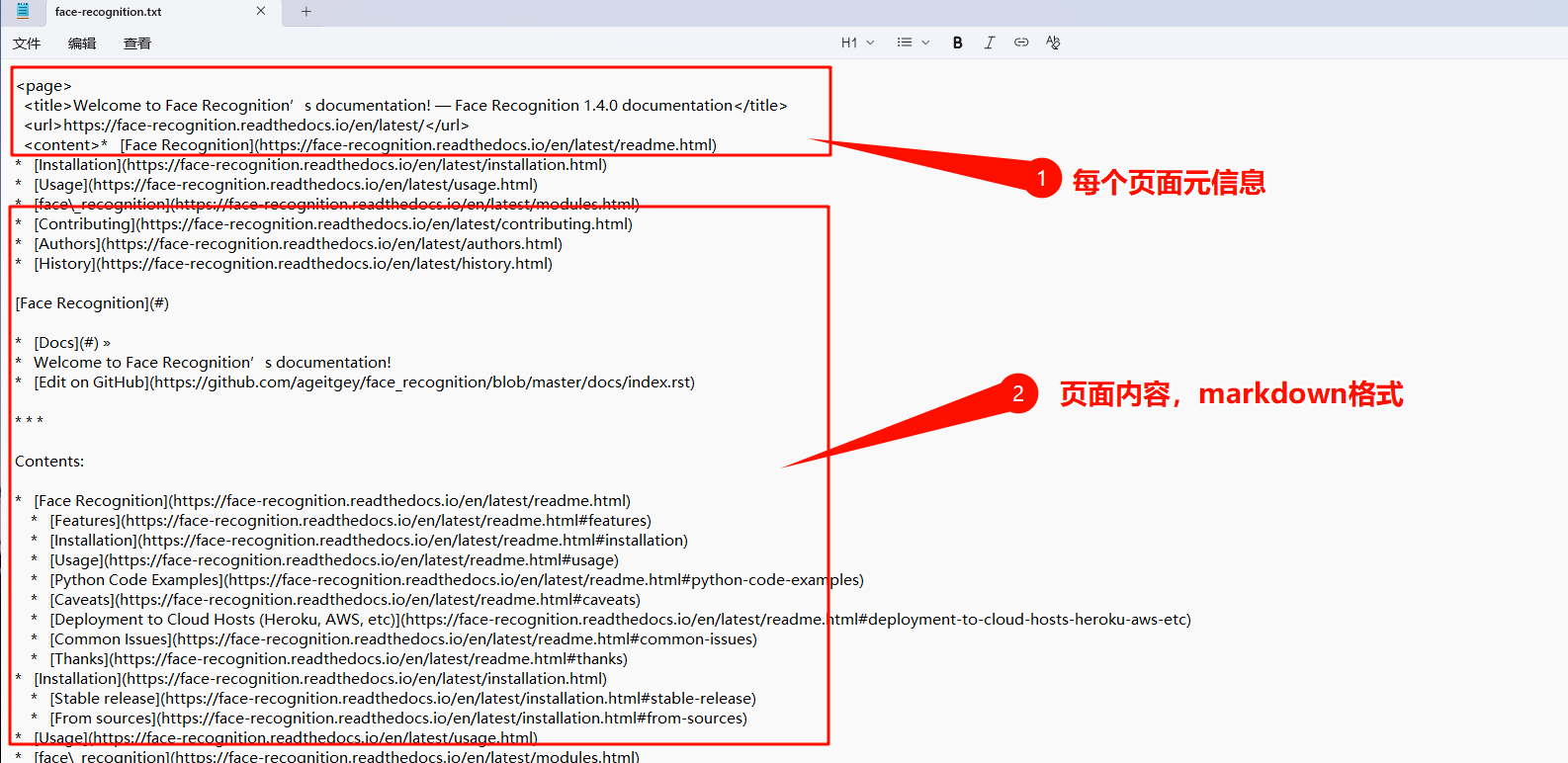
-
快速使用这个文件建立本地RAG知识库,可以参考文章:https://blog.luler.top/d/30
四、总结
- 这是一个非常有用的生产力小工具,递归抓取、markdown解析这些功能在建立RAG知识库需求中非常刚需
- 部分场景不适用,如不能自动分页(只是基于内容中存在的链接做深度挖掘),不能抓取动态渲染内容
- 代码是开源,提供API接入,也可以fork过来做扩展与调整
本站资料仅供学习交流使用请勿商业运营,严禁从事违法,侵权等任何非法活动,否则后果自负!
THE END





















暂无评论内容