









一、简介
- FunASR 是一个基本的语音识别工具包,提供多种功能,包括语音识别ASR等
- 基于FunASR,有很多可以直接使用的学术和工业级预训练模型,具有准确率高、效率高、部署便捷等优点,支撑语音识别业务的快速建设
- FunASR开源项目地址:https://github.com/modelscope/FunASR
- hello_asr是一个使用docker快速部署FunASR并转成API服务的工具,代码地址:https://github.com/luler/hello_asr
二、安装
- 准备好docker、docker-compose环境,可以不使用GPU,直接在CPU上运行
- 新建docker-compose.yml配置文件,配置内容如下:
version: '3' services: hello_asr: image: dreamplay/hello_asr:latest ports: - 12369:12369 restart: always - 在docker-compose.yml文件下一键运行(注意镜像包含模型和软件环境,会有点大,请耐心下载)
docker-compose up -d
三、使用示例
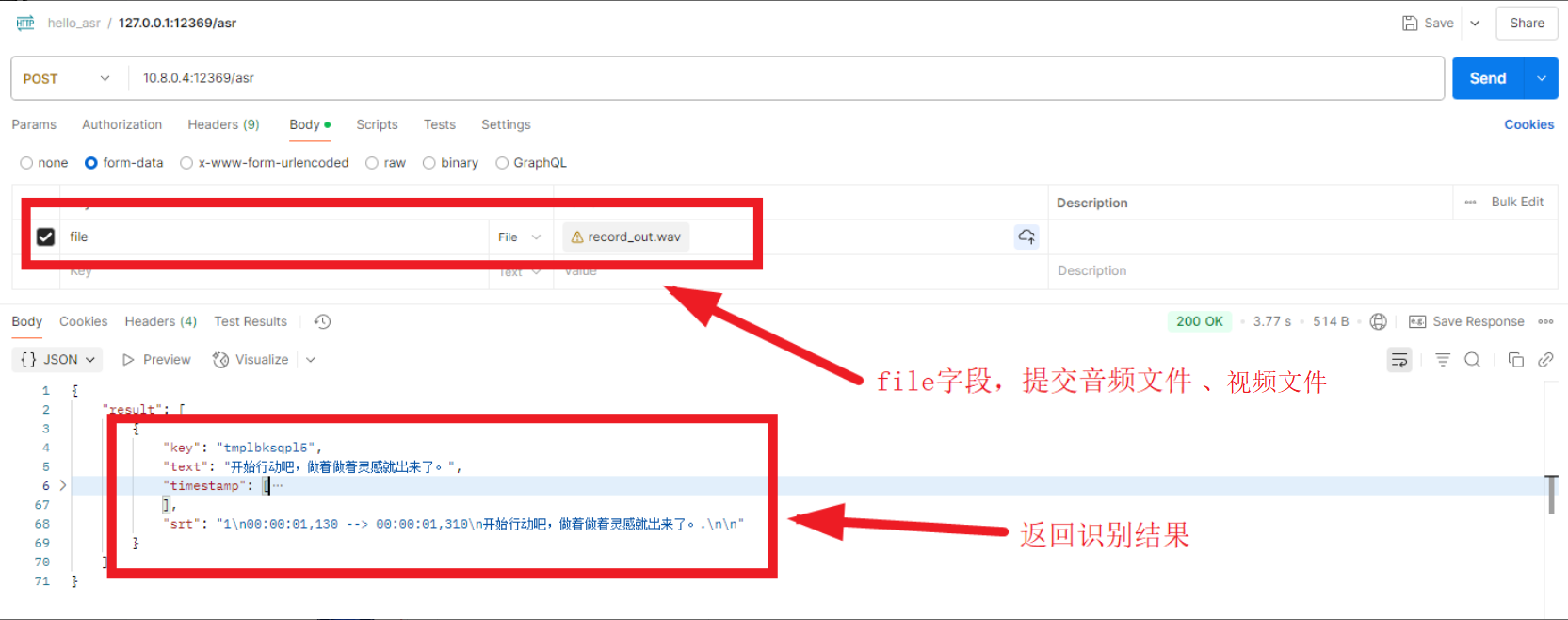
提供的接口:POST: http://127.0.0.1:12369/asr
- mp3、wav等音视频文件转成文字
- 使用funasr直接把上传的音频转换成文本信息
- 再根据funasr的转换结果,提取生成SRT字幕
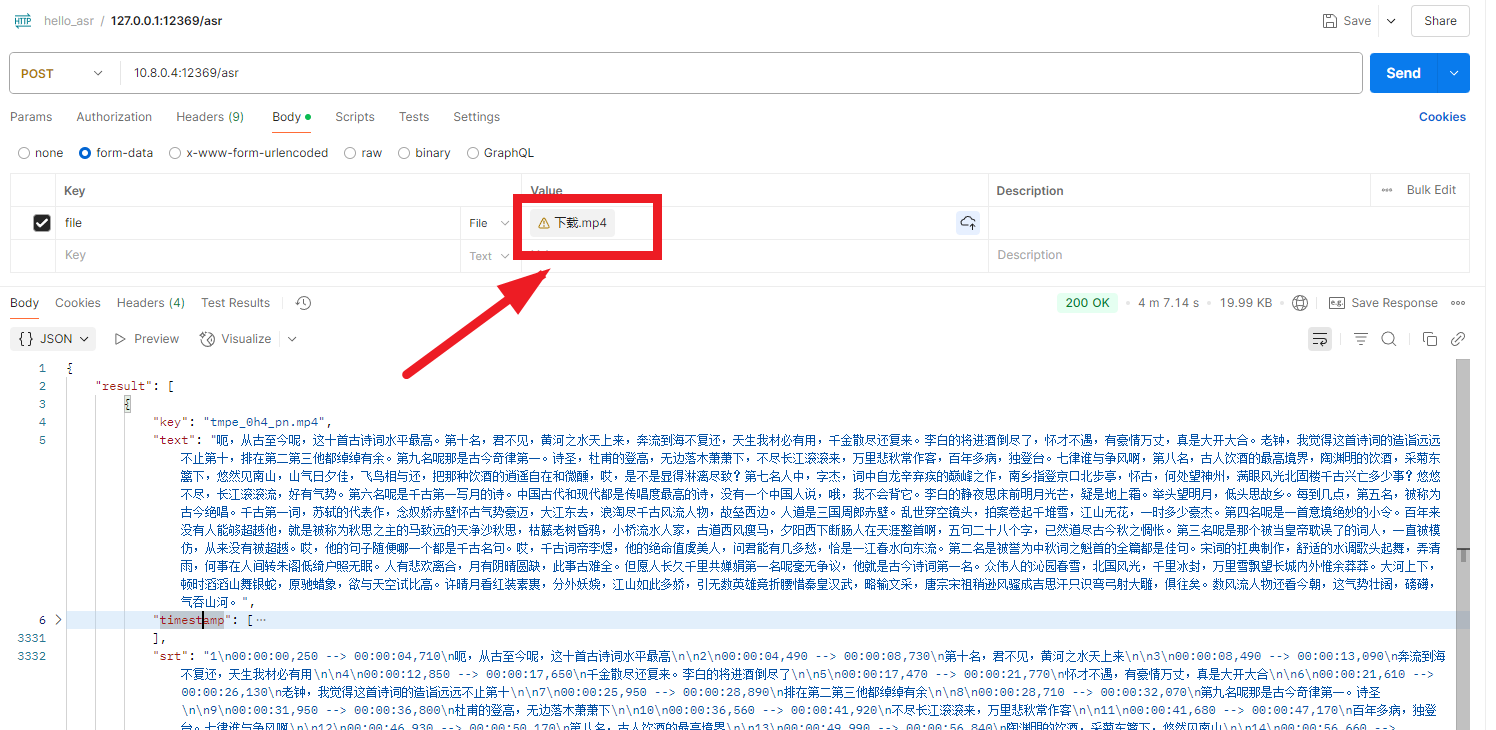
- mp4等视频文件转文字
- 原理就是通过ffmpeg把视频转成wav音频,再使用funasr对wav音频进行文本转换
四、总结
- 简单的提取音视频文本还是可以胜任的,音频识别准确率还是不错的
- 如果需要提高转换性能,需要使用GPU来启动
本站资料仅供学习交流使用请勿商业运营,严禁从事违法,侵权等任何非法活动,否则后果自负!
THE END






















暂无评论内容